Wazuh Migration: Missing Historical Alerts
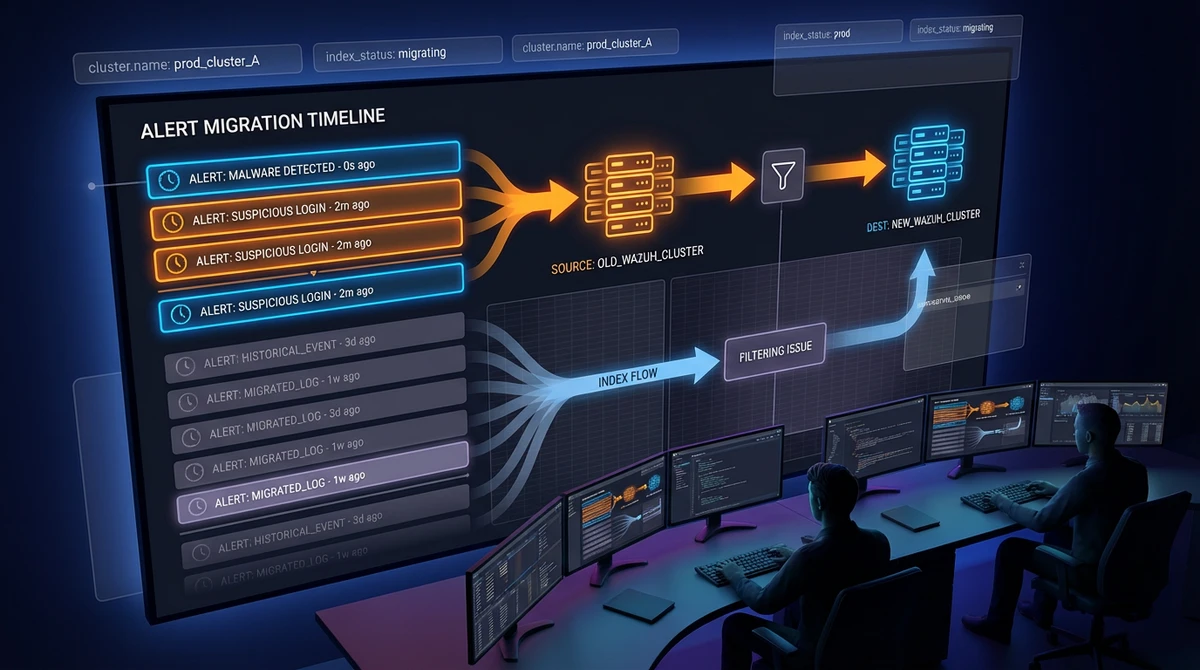
I hit this after a migration and it was confusing at first: Wazuh looked healthy, agents were still sending data, but older alerts were suddenly missing in built-in dashboards.
The important part: in many cases, the data is still there. What changed is how dashboards filter it.
I wrote this so you can spot the issue quickly and fix it without taking unnecessary risk in production.
Quick Take
- After migration, historical docs may have different identity metadata than current dashboards expect.
- Built-in views can hide those docs even though they still exist.
- Normalize the metadata with an ingest pipeline and reindex into a new index.
- Validate counts and visibility before any final cutover.
What I Saw
- New alerts showed up.
- Old alerts looked “gone” in dashboards.
- Discover still returned old events.
That combination is usually a visibility mismatch, not immediate data loss.
Why It Happens
Wazuh dashboard objects depend on alert metadata fields (commonly fields like manager.name or cluster.name) to scope data.
When you migrate from standalone to cluster, rename a cluster, or move to a manager with a different identity, historical indices can keep old metadata while newer data uses new values.
So dashboards apply filters that old docs no longer match.
Behavior depends on your Wazuh version and dashboard customizations, but this pattern is common in real migrations.
How To Avoid It Next Time
- Keep manager/cluster identity stable when possible.
- Decide naming conventions early and treat them as part of platform contract.
- Add metadata checks to migration runbooks, not only service health checks.
Safe Remediation Pattern
The safest approach I found is:
- Create an ingest pipeline that normalizes the expected field.
- Reindex old data into a new index through that pipeline.
- Validate counts and field values.
- Cut over in a controlled way.
- Keep rollback options until you finish verification.
Step-by-Step Runbook
The commands below normalize cluster.name to wazuh. Replace field and value to match your environment.
1) Create an ingest pipeline
PUT _ingest/pipeline/set-cluster-name-wazuh
{
"description": "Normalize cluster.name for migrated historical alerts",
"processors": [
{
"set": {
"field": "cluster.name",
"value": "wazuh",
"override": true
}
}
]
}2) Capture baseline count first
GET /wazuh-alerts-4.x-YYYY.MM.DD/_countSave this number.
3) Confirm target mapping/template behavior
If your cluster does not auto-apply the expected template to the new index name, create the target index first with the right settings/mappings before reindexing.
4) Reindex with the normalization pipeline
POST _reindex
{
"source": {
"index": "wazuh-alerts-4.x-YYYY.MM.DD"
},
"dest": {
"index": "wazuh-alerts-4.x-YYYY.MM.DD-fixed",
"pipeline": "set-cluster-name-wazuh"
}
}5) Validate before cutover
GET /wazuh-alerts-4.x-YYYY.MM.DD-fixed/_countPOST /wazuh-alerts-4.x-YYYY.MM.DD-fixed/_count
{
"query": {
"bool": {
"should": [
{ "term": { "cluster.name": "wazuh" } },
{ "term": { "cluster.name.keyword": "wazuh" } }
],
"minimum_should_match": 1
}
}
}Your baseline and reindexed counts should make sense, and your target field query should return expected results.
6) Cut over carefully
Use one of these approaches:
- Pattern cutover: keep
-fixednames and make sure your dashboard index patterns include them. - Alias cutover: move consumers to a stable read alias (for example,
wazuh-alerts-read) and point it to remediated indices.
If you use aliases, avoid name collisions: an alias cannot share the same name as an existing concrete index.
Before You Run This In Production
- Test on one non-critical historical index first.
- Confirm mappings/templates are compatible on the target index.
- Capture pre-change counts and representative sample documents.
- Validate dashboard visibility after reindex.
- Capture before/after screenshots of the same widgets.
- Keep rollback path and retention window before deleting originals.
- Execute during a planned maintenance window.
Reindex vs Update By Query
- Use
_update_by_querywhen only a small subset needs correction. - Use reindex + pipeline when most docs need normalization.
In larger environments, reindex is usually easier to reason about and audit.
Final Note
If you run into this, do not assume your history is lost. Check metadata consistency first.
In my case, the data was there, dashboards were filtering it out, and a controlled reindex workflow restored visibility without downtime surprises.